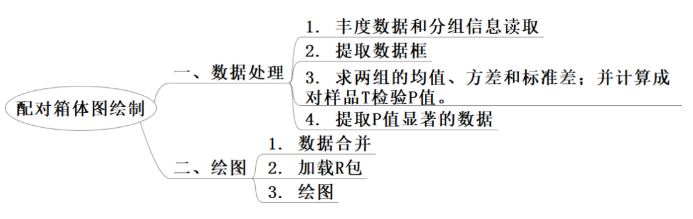

1. 丰度数据和分组信息读取
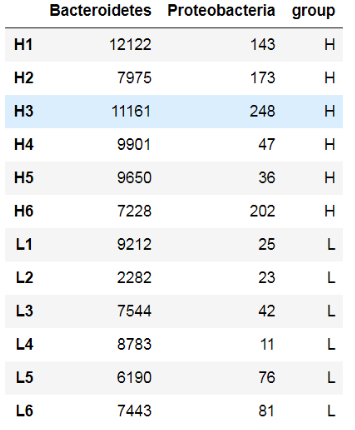
未处理的数据读取,以data表示;分组信息以info表示。
In [1]:
data = read.table('phylum.taxon.Abundance.xls',header = T,sep = 't',row.names = 1)
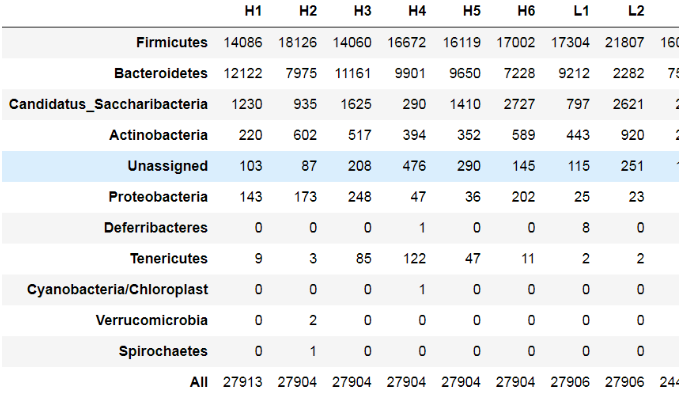
data
Out[1]:
In [2]:
info = read.table('sample_groups.xls',header = F,sep = 't',col.names = c('sample','group'))
info
Out[2]:

2. 提取数据框
通过grep获取All和Verrucomicrobia的行号
In [3]:
grep("All|Verrucomicrobia", rownames(data))
Out[3]:
10 12处理后的数据以数据框df表示。- grep("All|Verrucomicrobia", rownames(data)) 用于提取非All和Verrucomicrobia的行,info$sample提取样品列
In [4]:
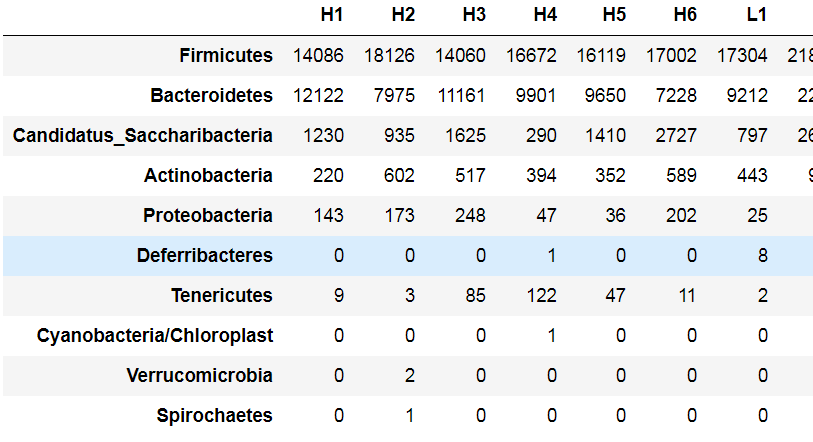
df = data[-grep("All|Unassigned", rownames(data)),info$sample]
df
Out[4]:
3. 求两组的均值、方差和标准差;并计算成对样品T检验P值。
In [5]:
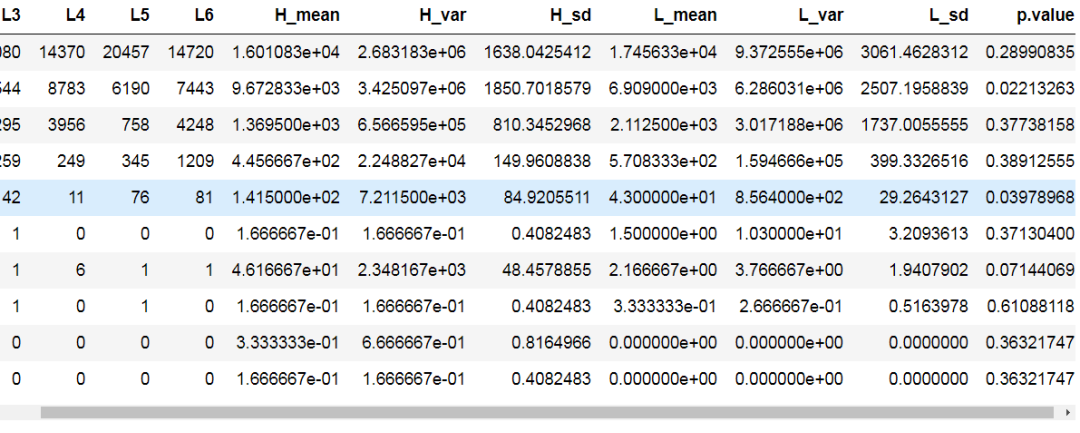
df['H_mean'] = apply(df[,info[info$group=='H',1]],1,mean)
df['H_var'] = apply(df[,info[info$group=='H',1]],1,var)
df['H_sd'] = apply(df[,info[info$group=='H',1]],1,sd)
df['L_mean'] = apply(df[,info[info$group=='L',1]],1,mean)
df['L_var'] = apply(df[,info[info$group=='L',1]],1,var)
df['L_sd'] = apply(df[,info[info$group=='L',1]],1,sd)
df['p.value'] = apply(df,1,function(x){ t.test(as.numeric(x[info[info$group=='H',1]]),as.numeric(x[info[info$group=='L',1]]),paired = T)$p.value })
df
Out[5]:
数据保存至文本文件phylum.taxon.Abundance.new.xls 中。
In [6]:
write.table(df,'phylum.taxon.Abundance.new.xls',sep = 't',row.names = T, col.names = NA,quote = F)
4. 提取P值显著的数据
In [7]:
df_diff = df[df$p.value<0.05,info$sample] df_diffOut[7]:


1. 数据合并
In [8]:
df_diff = data.frame(t(df_diff),group = info$group) df_diff
Out[8]:
2. 加载R包
In [9]:
.libPaths("C:/Program Files/R/R-3.6.1/library")
library(ggpubr)
3. 绘图
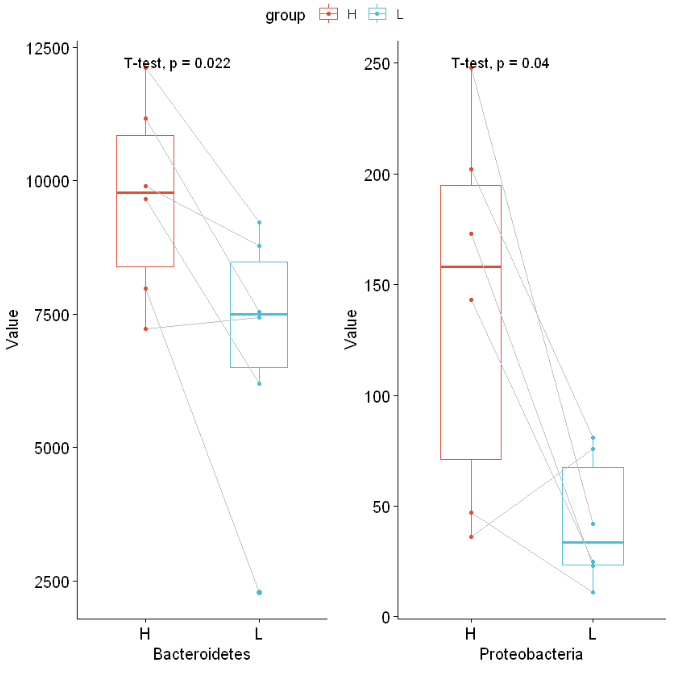
method包括:t.test、wilcox.test、anova、kruskal.test;本次分析采用t.test。
ggarrange可以将多个图绘制在一张图上,ncol=2 按照每行2张图绘制,行不限制。
In [10]:
p1= ggpaired(df_diff, x="group", y="Bacteroidetes", color = "group", line.color = "gray",xlab = 'Bacteroidetes',
line.size = 0.4, palette = "npg")+ stat_compare_means(method = "t.test",paired = TRUE)
p2= ggpaired(df_diff, x="group", y="Proteobacteria", color = "group", line.color = "gray", xlab = 'Proteobacteria',
line.size = 0.4, palette = "npg")+ stat_compare_means(method = "t.test",paired = TRUE)
ggarrange(p1, p2, ncol = 2,common.legend = T)
Out[10]:
![]()

往期相关链接:
1、R基础篇
【零基础学绘图】之绘制venn图(五);2、R进阶
【绘图进阶】之六种带中心点的PCA 图和三维PCA图绘制(四);
【绘图进阶】之交互式可删减分组和显示样品名的PCA 图(三);
3、数据提交
3分钟学会CHIP-seq类实验测序数据可视化 —IGV的使用手册;
10分钟搞定多样性数据提交,最快半天内获取登录号,史上最全的多样性原始数据提交教程;
20分钟搞定GEO上传,史上最简单、最详细的GEO数据上传攻略;
4、表达谱分析
表达谱分析(二)通路富集分析和基因互作网络图绘制;如何对GEO数据进行差异分析;miRNA靶基因预测软件__miRWalk 3.0;5、医学数据分析
KING: 样本亲缘关系鉴定工具;【WGS服务升级】人工智能软件SpliceAI助力解读罕见和未确诊疾病中的非编码突变;隐性疾病trio家系别忽视单亲二倍体现象——天昊数据分析助力临床疾病诊断新添UPD(单亲二倍体)可视化分析工具;【昊工具】Oh My God! 太好用了吧!疾病或表型的关键基因查询数据库,我不允许你不知道Phenolyzer;
天昊客户服务中心
手机/微信号:18964693703